



A recent trend has been noticed that our customers subscribe to data from 3rd party, process this data using their proprietary algorithm and sell the feed to their end customers. We help them design this data pipeline with minimum cost of operation – generally with serverless architecture. Being an AWS Consulting Partner, we will demonstrate this architecture on AWS.
Overview
In many cases, serverless architecture gives some significant competitive advantages over with-server architecture.
- Low cost – Pricing model is pay-as-you go. In addition, AWS gives a lot of free tiers on serverless components.
- Higher security – No OS patching, no machines to maintain needed. Minimum attack surface.
- Highly scalable – AWS maintains the infrastructure and AWS infrastructure is huge.
Use cases where this serverless architecture will fit. - When real-time insights are not required. This architecture is near-real time.
- There are large number of reasonable size messages (rather than extremely large number of small messages)
- Where data feed need not be strictly sequentially processed
- here at-least-once data consistency is acceptable (idempotent processes)
Architecture
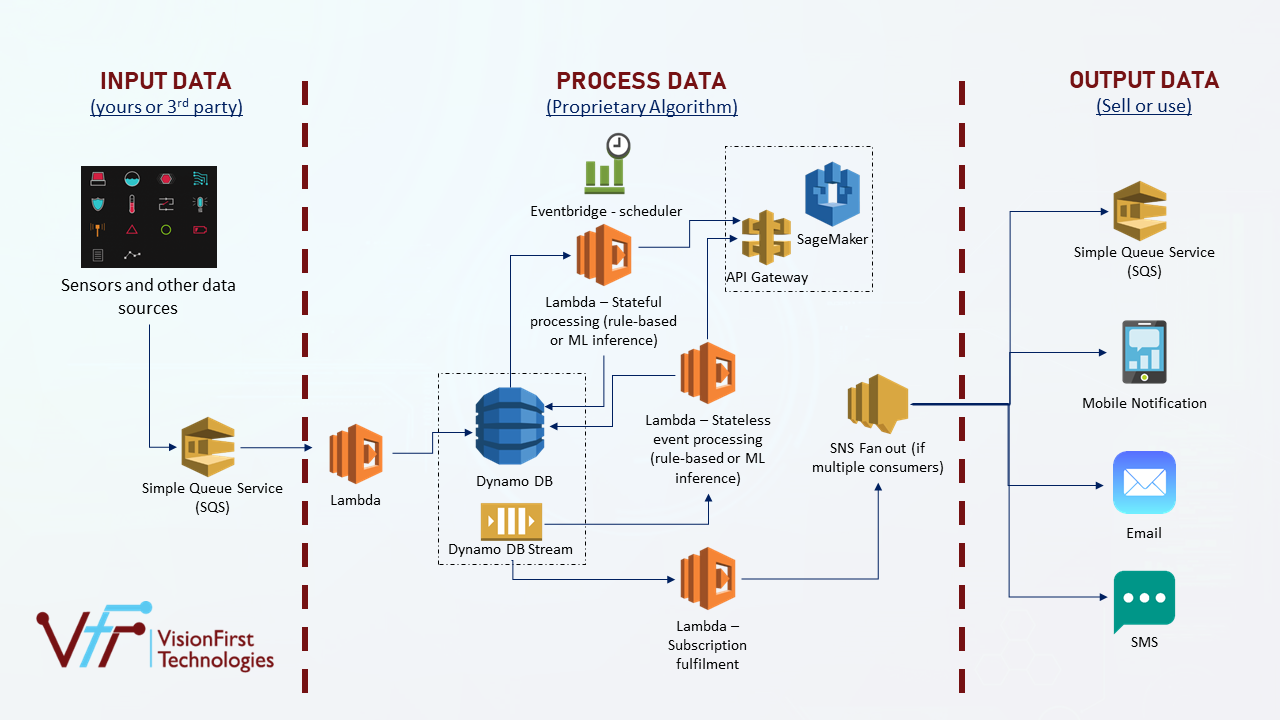
As per the earlier picture, the whole architecture has been divided into three areas:
- Input Data
- Process Data
- Output Data (transformed)
Input Data
All data (IOT, enterprise, 3rd party feed, tribal knowledge, …) can be fed into one or more SQS. A Lambda function listens to SQS in batch mode and inserts any new data into Dynamo DB table(s).
Process Data
There are two kinds of processing:
- Stateful processing: An EventBridge scheduler triggers a Lambda function at certain fixed interval (e.g., every 10 minutes). This Lambda function fetches data from Dynamo DB, executes pre-defined rules or invokes ML model inference. The Lambda then puts the result back into Dynamo DB table(s).
- Stateless processing: A Dynamo DB stream on appropriate Dynamo DB tables invoke a Lambda function whenever there is an insert, update or delete of a record in table. This Lambda may fetch more data from Dynamo DB and then it executes pre-defined rules or invokes ML model inference. The Lambda then puts the result back into Dynamo DB table(s).
For ML model inference
The model may reside in Sagemaker with an endpoint exposed via API Gateway or a model is present in S3. Lambda downloads that model from S3 and runs inference on that model.
Output Data
Since the desired output data is put back in Dynamo DB, a Dynamo DB stream invokes a Lambda function whenever there is a new record inserted. This Lambda then puts a record in SNS. This SNS further fans out this data to subscribers – mobile apps, email or another SQS.
If customers need to display feed from SQS to a user’s screen then web socket APIs can used for real-time refresh of feed on the screen or dashboard.
Conclusion
Data Pipeline with Serverless architecture is the new reality that can transform the whole process of processing data, VisionFirst Technologies is one of the leading AWS Consulting partners offering the same at its best.




Nexttrophy: Lessons from Building and Running a SaaS Sports Platform

What is BI (Business Intelligence)?
