



In continuation to AWS Batch – Part 1 (Introduction), we will discuss implementation design patterns in AWS Batch.
About this series
There are 3 articles in this series on AWS Batch.
- AWS Batch – Part 1 (Introduction)
- AWS Batch – Part 2 (Design Patterns)
- AWS Batch – Part 3 (A Real Life Example)
The key questions, milestones and tasks in running a batch job are as follows:
- Who will invoke and when a Batch job will be invoked
- How many parallel processes to be created
- Creating the parallel processes and setting inter dependency
- Execution and managing transient state
- Aggregation of result and sending for final consumption
- Cleaning up
- Keeping an eye on success and failure
Let’s deep dive.
1. Who will invoke and when a Batch job will be invoked
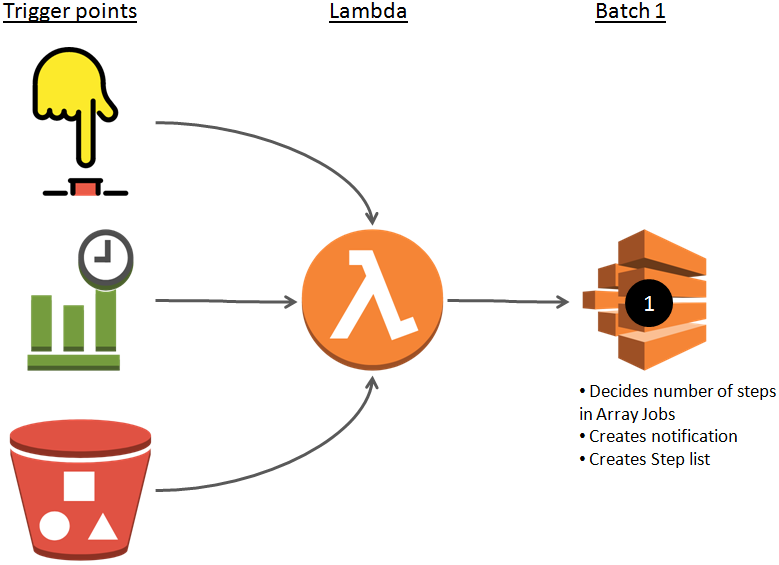
Most of the times, a batch job invoked by one of the following triggers:
- Schedule (every Sunday at 2:00 am UTC)
- Placement of an input file (put a file in S3 bucket)
- Manual invocation (click a push button on a screen)
- External notification (a webhook)
The invocation should trigger a Lambda function (serverless) that can create step 1 of Batch job. Read more about this Batch job in next step (2. How many parallel processes to be created).
2. How many parallel processes to be created
Most of the times, extent of work to be done in a batch is not known up front. For example: if we need to read an excel sheet and then process each record then we can only know number of records after we have read the excel sheet OR if we need to create Collaborative Filtering for item-to-item in Recommendation engine then we can get to know of all the items after we have analyzed all the items.
This step creates steps for each individual process (e.g one step per item-to-item in Recommendation engine) and stores data for each step (Array Job Item) in some storage (S3 bucket or Dynamo DB). Thereafter, it should send a notification (SNS) to create subsequent steps.
Read more about using SNS notification and subsequent invoking Lambda function in next step (3. Creating the parallel processes and setting inter dependency).
3. Creating the parallel processes and setting inter dependency
SNS notification from above step invokes a Lambda function that creates subsequent known batch jobs.
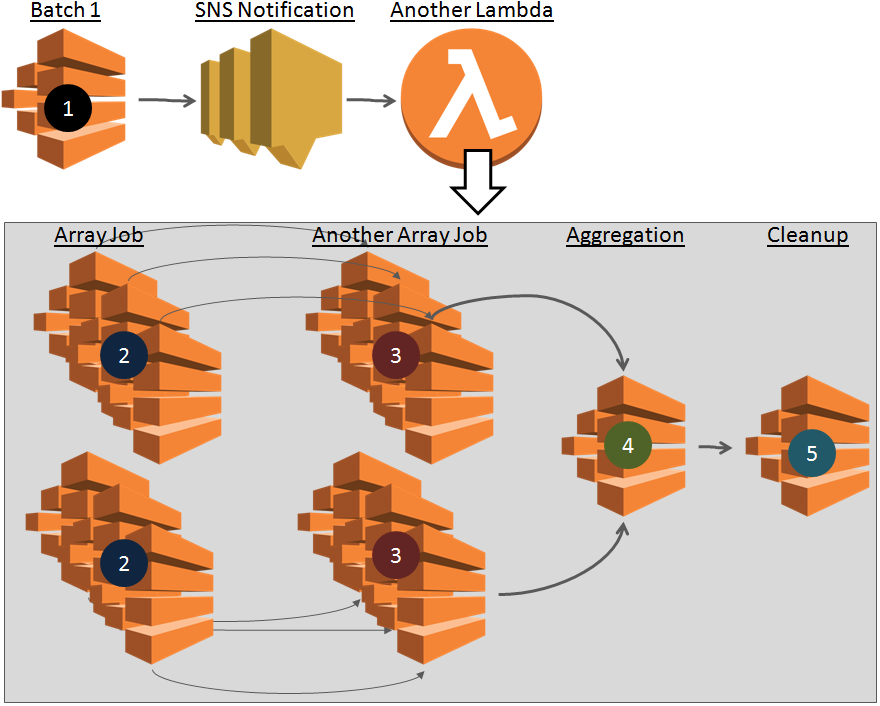
Creating SNS to submit subsequent batch jobs is a good idea for the following reasons:
- We do not overload Batch 1 with responsibility to create subsequent batch jobs
- If there is a failure in creating subsequent steps then only Lambda function will retry and not Batch 1 which can be heavily resource intensive
- Execution of Lambda is fast because it is only submitting jobs
At this stage, our visibility on next steps are as follows:
- Steps required in Array job: Clear Visibility. Clear understanding because previous SNS topic may give number of array jobs to be created with number of items and source of array items. These jobs do not have any dependency.
- Subsequent Array jobs: Clear Visibility. Sometimes there may be more array jobs with next array jobs dependent upon the same array item of previous job. We have visibility to create these jobs as well. We should create jobs with N to N dependency.
- Aggregation requirement: May or not have Clear Visibility. If aggregation is simple then we have clear visibility to create this batch. We should set dependency of these jobs on previous array job. If number of aggregation jobs varies with processing of Array job then we not have this visibility.
- Cleanup job requirement: Visibility depends on previous job. If we can create aggregation job then we should create cleanup job as well with dependency on all the aggregation jobs
Please note that all we are talking about this step in Lambda function execution is batch job submission and not the execution so this execution is very fast.
4. Execution and managing transient state
This part is the meat of AWS Batch. Lambda function above would have created a number of Array jobs depending upon number of items to be processed. Execution of job starts immediately (of course it waits for compute resources to become available) because it is not dependent upon any other job.
Each of the jobs gets its list of work for each array item from the input given by Lambda (further passed by Batch 1). The real data to be processed can be stored in any data store S3, DynamoDB or any other data store. The result of processing of each array item is stored back in a data store (S3, DynamoDB etc.).
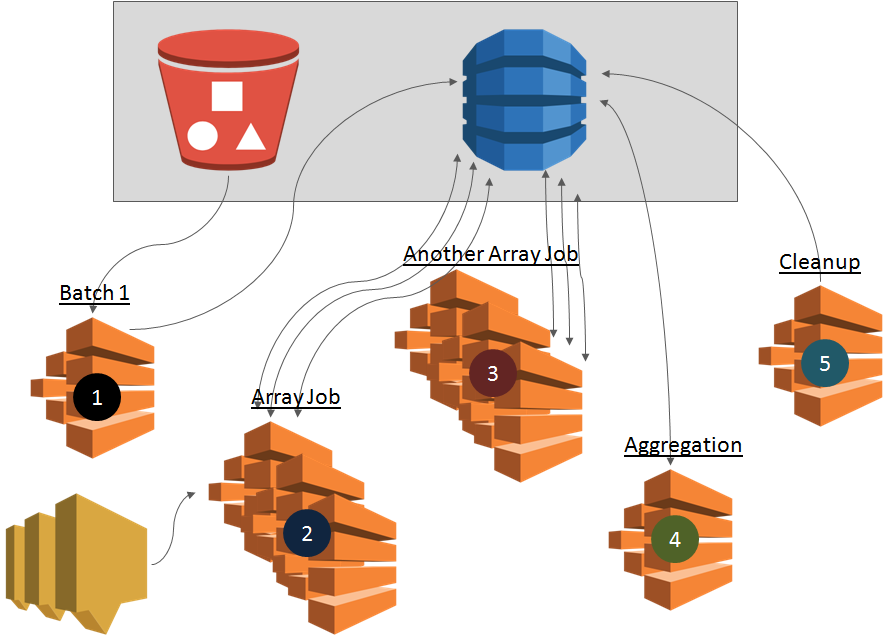
If there may be subsequent Array jobs with N to N dependency then subsequent jobs array items are processed when previous jobs array items complete execution. This process is highly multi-threaded.
Note that if there is a dependency on third party (e.g. web scrapping) then the third party system may become a bottleneck so you may want to slow down the overall process.
Lastly, if Array Jobs may create variable number of aggregation jobs depending upon the result of Array jobs then it is best to send a notification to create Aggregation jobs. This approach is similar to 3. Creating the parallel processes and setting inter dependency.
5. Aggregation of result and sending for final consumption
This should also be one or more Batch jobs that will take Array jobs as predecessor, do some aggregation and produce the result. The result can be data stored in DynamoDB, files created in S3 or some other information.
6. Cleaning up
Creating batch jobs (multiple array jobs), subsequent array jobs, aggregation, multi-node jobs etc. requires intermittent and transient storage in DynamoDB or S3. With a number of batch job execution, the data store will look messy. There are two ways to clean up:
- Setup housekeeping policies on S3, DynamoDB or other store
- Create a Batch job to cleanup (Recommended)
7. Keeping an eye on success and failure
It will be frustrating if an overnight job fails in an hour and we get to know of the failure next morning. It is so much easier to send a SNS notification when batch job failed event occurs. The notification can be used for informing the stakeholders, creating a support ticket or some other automation (resubmit the job or create another job).
Please refer to 7. Monitoring and notification for failed or successful jobs in AWS Batch – Part 1 (Introduction).
Back to you
Do you use some of these design patterns? Do you have some design patterns or best practices to share? What would you like to hear from us on Batches in subsequent articles? We would love to hear from you.
About VisionFirst Technologies Pvt. Ltd.
We are a group of researchers and practitioners of cutting edge technology. We are AWS Registered Partner. Our tech stack includes Machine Learning, offline/2G tolerant mobile apps, web applications, IOT and Analytics. Please contact us to know how we may help you.




Case Study: Enabling Offline Data Storage for a Crop Insurance Mobile Application

Cloud – an extension to your infrastructure
