



When we built Nexttrophy—a SaaS platform to help families discover and book sports tournaments and coaches—we knew that scalability, independence of features, and reliability were crucial.
In 2017, while microservices were still maturing for most startups, we made an early and bold choice: to break our platform into fully independent microservices with separate databases, asynchronous messaging, and search indexing.
In this post, we will walk you through the architecture, technology choices, challenges, and lessons learned, which later shaped our expertise in Kafka, Debezium, and Elasticsearch consulting.
Why Microservices for Nexttrophy?
Nexttrophy needed to serve multiple business domains—Tournaments, Coaches, Blogs, Payment Processing—all of which had different scalability and development needs.
Instead of creating a monolith, we embraced microservices, allowing each domain to:
- Scale independently.
- Have its own database and schema.
- Be developed and deployed without affecting others.
- Communicate asynchronously where possible.
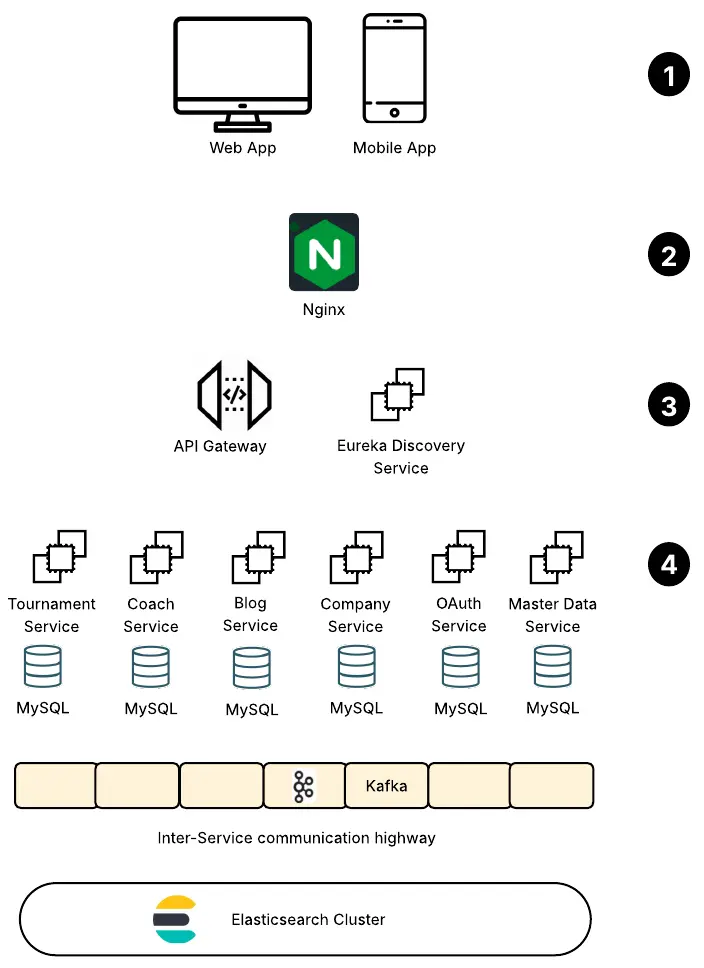
Core Technologies Chosen
| Component | Technology Used |
| Framework | Java + Spring Boot |
| Service Discovery | Netflix Eureka |
| API Gateway | Spring Cloud Gateway / Zuul |
| Database | MySQL (separate DB per service) |
| Inter-Service Messaging | Apache Kafka (3 brokers, 3 Zookeeper nodes) |
| Change Data Capture | Debezium (MySQL CDC) |
| Search Engine | Elasticsearch (3-node cluster) |
| Authentication | OAuth2 with JWT Tokens |
| Caching | Spring Cache Abstraction (@Cacheable) |
| API Documentation | Swagger |
| Payment Gateway | Paytm |
Service Landscape
We structured Nexttrophy into specialized microservices, each responsible for a domain:
| Service Name | Responsibility |
| nexttrophy-discovery | Eureka Service Discovery (started first) |
| nexttrophy-gateway | API Gateway—routes all client requests |
| nexttrophy-masterdata | Reference/master data (sports, cities, age groups) |
| nexttrophy-oauth | Authentication (JWT generation) |
| nexttrophy-tournament | Tournament listing, registration, updates |
| nexttrophy-coach | Coach profiles, bookings |
| nexttrophy-blog | Blogs and articles management |
| nexttrophy-company | Academy/Organizer profiles |
Service Discovery & Gateway
We used Netflix Eureka for service discovery—allowing dynamic detection of service instances without hardcoded IPs.
The API Gateway (Spring Cloud Gateway/Zuul) received all client requests, performing routing, SSL termination, and hiding internal service complexity from the outside world.
Asynchronous Communication via Kafka
To reduce tight REST dependencies and ensure scalability, we relied heavily on Apache Kafka:
- Events like “New Tournament Created”, “Coach Updated”, or “Payment Successful” were sent via Kafka.
- Any service interested in such events could consume them independently.
This event-driven architecture allowed our services to evolve without knowing each other’s details.
Cross-Service Data Synchronization with Debezium and Kafka
While Kafka enabled communication, some data consistency requirements couldn’t be met through REST or messages alone.
For true microservice independence, each service maintained its own MySQL database—but certain updates (like user info, payments) had to propagate system-wide.
We solved this using Debezium for Change Data Capture (CDC):
- Debezium monitored MySQL binlogs in each service’s DB.
- Changes were streamed into Kafka topics.
- Other services consumed these topics to keep derived data in sync.
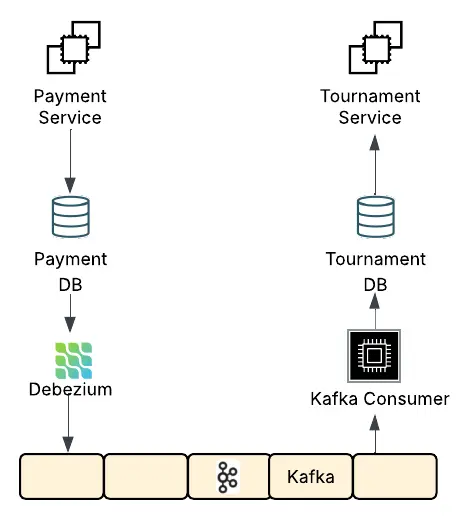
For example:
- When a payment succeeded, Debezium captured the database change in the Payment Service and published it to Kafka.
- Tournament, Company or other services could consume this Kafka topic and update their own state or trigger processes.
Operational Learnings
- Snapshot vs Streaming: Debezium sometimes required full DB snapshots—we learned to plan and manage these carefully to avoid delays.
- Failure Handling: We became adept at resetting connectors, handling re-snapshots, and replaying Kafka events to recover from failures.
- Kafka Topic Management: Good partitioning, retention settings, and consumer handling were critical to ensure smooth operation and avoid data loss.
Search with Elasticsearch
For fast, full-text search (tournaments, coaches, blogs), we maintained a 3-node Elasticsearch cluster:
- Indexed data streamed via Kafka/Debezium events,
- Provided rich search/filtering without hitting the core databases,
- Enabled real-time content discovery for users.
Authentication with OAuth2 & JWT
Authentication was centralized in the OAuth Service, issuing JWT tokens for secure, stateless authentication across services.
This eliminated session sharing, improved scalability, and enabled easy token validation by each microservice.
Caching with Spring Cache
For frequently requested reference data (e.g., sports types, cities), we used Spring’s in-memory caching (@Cacheable) in the MasterData Service, reducing DB hits and improving latency.
Lessons Learned
- Microservices were the right choice for this feature-diverse platform.
- Kafka + Debezium + Elasticsearch became our strongest tech areas—deep operational handling led to future client consulting.
- Eureka & Gateway were simple but had limits—today, we’d likely use Kubernetes Ingress or Service Mesh.
- Running Kafka, Zookeeper, and Debezium clusters required strong DevOps practices—experience that served us in future cloud-native projects.
Conclusion
The backend architecture of Nexttrophy helped us build a modular, scalable sports SaaS platform—one that handled high data freshness, asynchronous processing, and flexible growth paths.
The depth we gained in Kafka, Debezium, and Elasticsearch became valuable assets that shaped our consulting services in later years.
In the next post, we’ll shift focus to the Frontend architecture—how Angular SSR, Nginx, and a custom CDN solved SEO and performance challenges for this platform.




Artificial Intelligence in HR: Blending Intelligence with Empathy

Confidential Computing – Capture SSN and Store Safely
