



In continuation to our previous articles on AWS Batch, here we present a real life example of AWS Batch implementation. In this implementation, we used AWS Batch for massive parallel information extraction (website scraping) job. The same pattern can be used for Machine Learning model training, generating recommendations from customer usage pattern, complex scientific inference etc.
About this series
There are 3 articles in this series on AWS Batch.
- AWS Batch – Part 1 (Introduction)
- AWS Batch – Part 2 (Design Patterns)
- AWS Batch – Part 3 (A Real Life Example)
About Our Customer: Cattleman HQ
Cattleman HQ is dedicated to helping cattleman by providing profitable solutions to their marketing and production needs. Its tagline reads
Maximize the value of your cattle operation with auction marketing analytics
Please refer to https://cattlemanhq.com for more details.
Project Requirement
Customer wanted to extract tax due for all the customers from a public data source for certain customers, to consolidate the result and then to review their credit worthiness.
Start of process: Upload an excel sheet with list of customer information.
End of process: Send an excel file with credit worthiness of the required customers to organizer’s email address. If process fails then too send an email so that corrective action can be taken.
What is inherent in this process?
- The data source has its own speed of retrieving and providing information
- Number of customers is huge so lot of extraction is required
- Data source may sometimes fail while extracting information so retry mechanism is required.
Our Solution
We implemented the solution as per design pattern described in AWS Batch – Part 2 (Design Patterns).
We choose AWS Batch for its ability to perform massively parallel processing, to orchestrate multiple processes (sequential and parallel), to implement retry mechanism in case of a failure, and to provide serverless architecture. AWS Step Function is next close solution for the requirement however AWS Batch was better with all the features readily available.
VisionFirst Technologies Private Limited designed and developed a Web Scraping System as per customer requirement in which we used AWS Batch (inherently used ECS Fargate and ECR), AWS Lambda, SNS, SES, DynamoDB and S3. Please refer below for exact process.
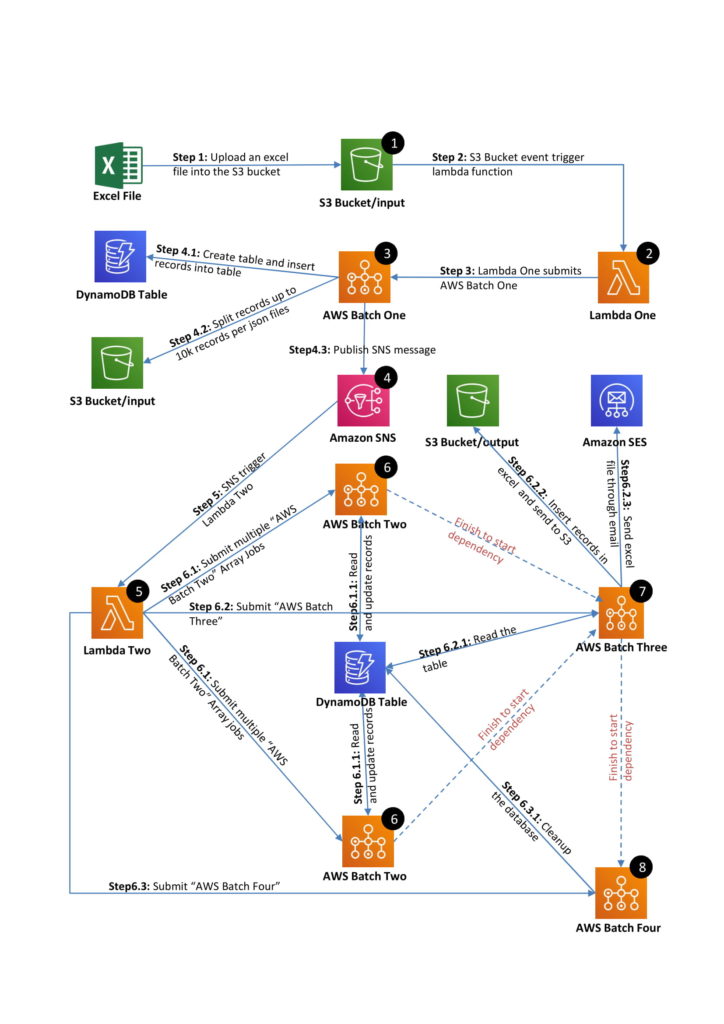
Step1: Upload an excel file into the S3 bucket | Step2: S3 Bucket event trigger lambda function | Step3: Lambda One submits AWS Batch One
Customer uploads an excel file in a specified folder in S3 bucket. Alternatively, this upload can be replaced by a webapp or API to upload the file at that location. Please refer to our other solution Innovating in a Time of Covid-19: A Serverless E-Compliance Conversion for similar implementation.
Once the file has been uploaded, S3 event triggers a Lambda function – Lambda 1.
This Lambda function submits AWS Batch One.
Step4.1: Create table and insert records into table | Step4.2: Split records per JSON files (max 10K records) | Step4.3: Publish SNS message
This Batch reads the excel file, creates a DynamoDB table for the current run and put the records into that table. This step also includes data cleansing and first level of aggregation that makes this step important for next steps.
We know that AWS Batch of Array type can run with up to 10K steps, so we processing input records and create one or more JSON files so that each file has maximum 10K records.
AWS Batch One triggers a notification to the SNS to initiate subsequent steps. Once SNS notification is pushed, the next Lambda function gets triggered.
Step 5: SNS triggers Lambda Two | Step 6.1: Submit multiple “AWS Batch Two” Array Jobs | Step 6.2: Submit “AWS Batch Three” | Step6.3: Submit “AWS Batch Four”
Lambda Two submits AWS Batch Two, AWS Batch Three and AWS Batch Four. These batches have finish-to-start dependency so next batch will not run until previous batch job has finished. If any of the batch in the sequence fails then subsequent jobs also fail.
AWS Batch Two: Lambda Two reads the location of JSON files and creates multiple AWS Batch Two according to number of JSON files. We have kept number of records per JSON to be 10K or less because that is the maximum limit of Array Job.
AWS Batch Two does the heavy lifting of reading a record per step from JSON, scraping from data source, retry if source does not respond, do first level of validation and update the information in Dynamo DB table. All the steps in this batch can be performed parallel provided the source systems are capable of service lot of parallel requests. We tried with 2048 vCPU and AWS created Spot instances on ECS Fargate like a charm.
Step 6.2.1: Read the table | Step 6.2.2: Insert records in excel and send to S3 | Step6.2.3: Send excel file through email | Step 6.3.1: Cleanup the database
AWS Batch Three consolidates the work done by AWS Batch Two, creates an excel sheet of output, stores in S3 bucket for later reference and sends the file to desired user through email (SES).
AWS Batch Four cleans up the transaction table created in Dynamo DB, cleans up JSON files and other temporary files created in S3.
End of AWS Batch Four marks successful completion of the process. Hurray!!
About VisionFirst Technologies Pvt. Ltd.
We are a group of researchers and practitioners of cutting edge technology. We are AWS Registered Partner. Our tech stack includes Machine Learning, offline/2G tolerant mobile apps, web applications, IOT and Analytics. Please contact us to know how we may help you.




Decoding Business Intelligence Architecture For Informed Decision Making

Staying Ahead: AWS Backup for Compliance and Security
